SPEECH SYNTHESIS – 21126
Speech synthesis, also called voice synthesis, is the electronic generation of sounds that mimic the human voice. These sounds can be generated from digital text or from printed documents. Speech can also be generated by high-level computers that have artificial intelligence (AI), in the form of responses to stimuli or input from humans or other machines.

What is a voice?
All audible sounds consist of combinations of alternating-current (AC) waves within the frequency range from 20 Hz to 20 kHz. (A frequency of 1 Hz is one cycle per second; 1 kHz = 1000 Hz.) These take the form of vibrations in air molecules. The patterns of vibration can be duplicated as electric currents.
A frequency band of 300 to 3000 Hz is wide enough to convey all the information, and also all of the emotional content, in any person’s voice. Therefore, speech synthesizers only need to make sounds within the range from 300 to 3000 Hz. The challenge is to produce waves at exactly the right frequencies, at the right times, and in the right phase combinations. The modulation must also be correct, so the intended meaning is conveyed. In the human voice, the volume and frequency rise and fall in subtle and precise ways. The slightest change in modulation can make a tremendous difference in the meaning of what is said. You can tell, even
over the telephone, whether the speaker is anxious, angry, or relaxed. A request sounds different than a command. A question sounds different than a declarative statement, even if the words are the same.
Tone of voice
In the English language there are 40 elementary sounds, known as phonemes. In some languages there are more phonemes than in English; some languages have fewer phonemes. The exact sound of a phoneme can vary, depending on what comes before and after it. These variations are called allophones. There are 128 allophones in English. These can be strung together in myriad ways.
The inflection, or “tone of voice,” is another variable in speech; it depends on whether the speaker is angry, sad, scared, happy, or indifferent. These depend not only on the actual feelings of the speaker, but on age, gender, upbringing, and other factors. A voice can also have an accent.
You can probably tell when a person speaking to you is angry or happy, regardless of whether that person is from Texas, Indiana, Idaho, or Maine. However, some accents sound more authoritative than others; some sound funny if you have not been exposed to them before. Along with accent, the choice of word usage varies in different regions. This is dialect. For robotics engineers, producing a speech synthesizer with a credible “tone of voice” is a challenge.
Record and playback
The most primitive form of speech synthesizer is a set of tape recordings of individual words.You have heard these in automatic telephone answering machines and services.Most cities have a telephone number you can call to get local time; some of these are word recordings. They all have a characteristic choppy, interrupted sound.
There are several drawbacks to these systems. Perhaps the biggest problem is the fact that each word requires a separate recording, on a separate length of tape. These tapes must be mechanically accessed, and this takes time. It is impossible to have a large speech vocabulary using this method.
Reading text
Printed text can be read by a machine using optical character recognition (OCR), and converted into a standard digital code alled ASCII (pronounced “ASK-ee”). The ASCII can be translated by a digital-to-analog converter (DAC) into voice sounds. In this way, a machine can read text out loud. Although they are rather expensive at the time of this writing, these machines are being used to help blind people read printed text.
Because there are only 128 allophones in the English language, a machine can be designed to read almost any text.However, machines lack a sense of which inflections are best for the different scenes that come up in a story.With technical or scientific text, this is rarely a problem, but in reading a story to a child, mental imagery is crucial. It is like an imaginary movie, and it is helped along by the emotions of the reader. No machine yet devised can paint pictures, or elicit moods, in a listener’s mind as well as a human being. These things are apparent from context. The tone of a sentence might depend on what happened in the previous sentence, paragraph, or chapter. Technology is a long way from giving a machine the ability to understand, and appreciate, a good story, but nothing short of that level of AI will produce a vivid “story movie” in a listener’s mind.
The process
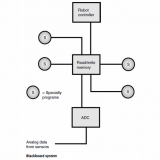
There are several ways in which a machine can be programmed to produce speech. A simplified block diagram of one process is shown in the